In Python’s Numpy library lives an extremely general, but little-known and used, function called einsum() that performs summation according to Einstein’s summation convention. In this tutorial article, we demystify einsum().
The only thing that the reader should need is an understanding of multidimensional Linear Algebra and Python programming. The reader will be better-prepared if he has, in the past, implemented the classic matrix multiplication using three nested loops in the language of his choice.
Why you should learn about it
The Einstein summation convention is the ultimate generalization of products such as matrix multiplication to multiple dimensions. It offers a compact and elegant way of specifying almost any product of scalars/vectors/matrices/tensors. Despite its generality, it can reduce the number of errors made by computer scientists and reduce the time they spend reasoning about linear algebra. It does so by being simultaneously clearer, more explicit, more self-documenting, more declarative in style and less cognitively burdensome to use. Its advantages over such things as matrix multiplication are that it liberates its user from having to think about:
- The correct order in which to supply the argument tensors
- The correct transpositions to apply to the argument tensors
- Ensuring that the correct tensor dimensions are lined up with one another
- The correct transposition to apply to the resulting tensor
The only things it requires are knowledge of:
- Along which dimensions to compute (inner/element-wise/outer) products.
- The desired output shape.
As an aside, Einstein summation is indeed named after the famed physicist and theoretician Albert Einstein. However, Einstein had no part in its development. He merely popularized it, by expressing his entire theory of General Relativity in it. In a letter to Tullio Levi-Civita, co-developer alongside Gregorio Ricci-Curbastro of Ricci calculus (of which this summation notation was only a part), Einstein wrote:
I admire the elegance of your method of computation; it must be nice to ride through these fields upon the horse of true mathematics while the like of us have to make our way laboriously on foot.
High praise indeed coming from Einstein himself!
NB: As a further aside, the most general formulation of Einstein summation involves topics such as covariance and contravariance, indicated by subscript and superscript indices respectively. For our purposes, we will ignore co-/contravariance, since we can and will choose the “basis” we operate in to make the complexities that they introduce disappear.
How it Works
While einsum()‘s Numpy documentation may be totally opaque to some, it operates on a simple principle and is enlightening once understood.
External Interface
The only dependency is Numpy.

It is invoked with a format string and any number of argument Numpy tensors, and returns a result tensor.

This format string contains commas (,) that separate the specifications of the arguments, as well as an arrow (->) that separates the specifications of the arguments from that of the resulting tensor. The number of argument specifications and the number of arguments must match, and exactly one arrow followed by a result specification must be present 1.

The specification of the arguments and result tensors are a series of (alphabetical, ASCII) characters. The number of characters in a tensor’s specification is exactly equal to the number of dimensions of this tensor.

Complete examples of einsum() format strings are first shown below. Try to guess what the result will be! Note that 0-dimensional tensors (scalars) are valid as both argument and result; They are represented by empty strings "". A reminder, again, that the specifications must be composed exclusively of ASCII lower or upper-case letters. Numpy will throw an error for anything else.

Internal Workings
In both Einstein summation and Numpy’s einsum(), one labels every axis of every tensor with a letter that represents the index that will be used when iterating over that axis. einsum() is then easily expressed as a deeply-nested set of for-loops. At the heart of these for-loops is a summation of products of the arguments. Those arguments are indexed precisely as the format string suggests. An elaborate example is below.

It should be now clear how the format string specifications relate to the dimensionality of the arguments and result, and how indices plop into place in the order given by the format string.
The astute reader will have noticed that in the matrix multiplication example above, there are four axes in total between all input arguments, but only three different indices (k is reused), and thus only three nested loops. That’s because we march in lockstep along the columns of A and the rows of B. We will get back later to the idea of index reuse, but first we must distinguish between two types of indices.
All indices in an Einstein summation or einsum() format string can be partitioned in two sets: The set of free indices, and the set of summation indices. The difference is quite simple:
- Free indices are the indices used in the output specification. They are associated with the outer
for-loops. - Summation indices are all other indices: those that appear in the argument specifications but not in the output specification. They are so called because they are summed out when computing the output tensor. They are associated with the inner
for-loops.
In light of this partition, the role of each is clear: Free indices are those used to iterate over every output element, while summation indices are those used to compute and sum over the product terms required.
Of course, the specific summations of products made are in part a function of the free indices. For instance, in the matrix multiplication example below, the output’s element [i,j] depends on a sum of products along row i of A and column j of B.

Meanwhile, summation indices are used exclusively within the inner-most loops:

More Examples
It is time for a little break. To let the above sink in, view also the following four other examples of einsum() calls, as well as the for-loops they map to.
2-D Matrix Diagonal Extraction

Note how the index i is reused twice in the same term. There is nothing about for-loops or arrays that forbids you from doing this, so einsum() doesn’t stop you from doing it. Of course, this only works if the matrix is square.
2-D Matrix Trace

Watch how the only difference between the trace and the diagonal is the absence of the output dimension i. The consequence is that the output is scalar, and thus there are no free indices. The index i, previously a free index, has become a summation index that collects the diagonal terms.
Quadratic Form

This is just a display of a 3-argument Einstein summation.
Batched Outer Product

If you had a matrix of NB vectors P and Q, and wanted to compute the outer product of the B‘th row of P and the B‘th row of Q for all B, you would be at pains to do this with other functions, and could easily get it wrong. With einsum(), it is trivial, even intuitive: Merely specify the batch index (here, 'B') in all terms.
If you wanted the outer-products to also be transposed, this is also trivial to accomplish. One only needs to use, instead of "Bi,Bj->Bij", the format-string "Bi,Bj->Bji". In no other Numpy function do arbitrary transpositions like this come at 0 additional cost in characters or time spent thinking.
Rules of Use
Almost all rules constraining your use of einsum() derive directly from its formulation as a set of nested loops indexed by named indices that sum products of its arguments indexed in a given way. As above, we will assume that an axis to which index letter 'x' is assigned has length 'Nx' for the purposes of the code snippets below.

In the first example above, if we know that the two arguments to the matrix multiplication "ik,kj->ij" are of shape (Ni,Nk) and (Nk,Nj), then we know that the output will have shape (Ni,Nj), because that is the length of the two surviving axes, one from each argument matrix.
Similarly, when we extract a diagonal, we implicitly assume the matrix to be square along those dimensions. If this were not so, a scalar loop would stop too early or late and possibly crash the program.
Here are examples of einsum() misuses:
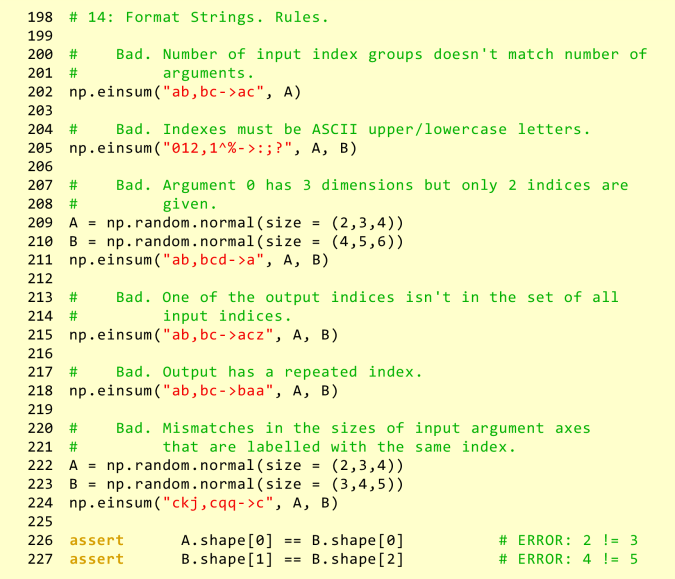
Again, when viewed as a deeply-nested set of loops that compute (scalar) sums of products, many of these rules make sense.
- The number of argument specifications must match the number of arguments, or else you are indexing into air.
- The argument specification string must be as long as the argument’s dimensionality, or else the
totalbeing summed into won’t be a scalar 2. - Using an output index that doesn’t exist amongst the input indices would be like using an undeclared variable.
- Reusing an index in the output specification would leave uninitialized elements outside a diagonal.
- Using the same index for axes of different lengths doesn’t make sense – which is the right length to use?
MLP
For real-world applications of einsum(), let’s implement an MLP. An MLP has 3 axes of interest to us:
- Input unit axis
- Hidden unit axis
- Output unit axis
We give them the very appropriate labels/indices 'i', 'h' and 'o', and give them lengths Ni, Nh and No. We arbitrarily declare the weight matrices W and V to have shape (Nh,Ni) and (No,Nh); Their corresponding einsum() specifications are "hi" and "oh". We can now write very elegantly the MLP’s fprop and bprop procedures:

Note the total absence of any explicit transpositions in the code, and the total lack of care given to ordering of the parameters. einsum() is resistant to permutations of its arguments, so long as the format string’s argument specifications follow suit.
But, what if we wanted to vectorize this procedure, by processing batches instead? If we had written the MLP using the classic dot(), tensordot(), outer() and other similar functions, we’d be introducing transpositions left and right, and reordering the arguments so that dimensions line up in order to satisfy the requirements of those functions.
Witness instead what happens with an einsum() implementation. In addition to the axes listed above, we introduce a new axis:
- Batch number axis
and give it the index/label 'B' and length batch_size. We now make only a few edits to our implementation:

Almost the only thing it took us was to add 'B' to the output specifications of all activations and the gradients with respect to those activations! To obtain the gradient average across all examples, we instruct einsum() to sum out the batch axis 'B' by not giving it in the output specification, and divide einsum()‘s output by the length of that axis to normalize.
Philosophy
In general, the following points should be kept in mind when using einsum():
- Give each axis that notionally exists within the problem its own label. It is best if memorable ones can be chosen, like in the MLP problem above.
- If you want element-wise multiplication between the axes of two arguments, use the same index for both (
"a,a->a"). - If you want summation along a given axis, don’t put its index in the output specification (
"a->"). - If you want an inner product, which is element-wise multiplication between two axes followed by the summing-out of those axes, then do both of the above (
"a,a->"). - If a tensor is used as argument to
einsum(), simply copy-paste its specification from theeinsum()that created it. Input transpositions are automagically handled. - For the output, simply state what is the form of the tensor that you want. The genie in
einsum()will give it to you, and you have infinite wishes.
Useful Format Strings
Here is a list of useful operations, given as format strings. Remember that you can always reorder the argument specifications and the arguments in like manner, and that transpositions of the output are done simply by rearranging the letters in the output specification. Feel free to suggest more clever formats!
- Vector inner product:
"a,a->"(Assumes two vectors of same length) - Vector element-wise product:
"a,a->a"(Assumes two vectors of same length) - Vector outer product:
"a,b->ab"(Vectors not necessarily same length.) - Matrix transposition:
"ab->ba" - Matrix diagonal:
"ii->i" - Matrix trace:
"ii->" - 1-D Sum:
"a->" - 2-D Sum:
"ab->" - 3-D Sum:
"abc->" - Matrix inner product
"ab,ab->"(If you pass twice the same argument, it becomes the square of the matrix L2 norm) - Left-multiplication Matrix-Vector:
"ab,b->a" - Right-multiplication Vector-Matrix:
"a,ab->b" - Matrix Multiply:
"ab,bc->ac" - Batch Matrix Multiply:
"Yab,Ybc->Yac" - Quadratic form / Mahalanobis Distance:
"a,ab,b->" - …
Brain Teaser
What type of argument(s) do "->" and ",->" take, and what do they do with them?
Footnotes
- Actually, not quite. I’m presenting to you only the most explicit form of einsum’s format string. It is possible to omit
->and the output specification. If you do so, Numpy expands the format string automatically by making a “reasonable” guess at what the free indices, and thus the output specification, should be. Numpy assumes that all indices that are used only once in the format string are the free indices, and sorts them ASCIIbetically to create the output specification. For instance,"ij,jk"expands to"ij,jk->ik"(iandkare used once,iis ASCIIbetically first),"ii"expands to"ii->"(no indices are used only once, so the output is a 0-dimensional, scalar tensor) and"acb"expands to"acb->abc"(a,b,call used only once and sorted ASCIIbetically). - That’s another white lie.
einsum()supports broadcastable axes by specifying...instead of a single letter. But that’s a truly advanced feature.
Source Code
Pastebin link: http://pastebin.com/9GPvxwUn

Pingback: Simple update | alexandrelehoux
nice post, I lost so much time debugging np.dot()
I once check your code on your github and saw you used np.einsum() but didn’t put much attention. I just realize why you use it now, it’s so easy and intuitive.
Anyway continue the good work, if you have other good tips about numpy or anything, I’ll be one of your readers.
LikeLike
Oh no problem. Given more time I could even translate this to French.
Now I didn’t mention the two reasons not to use this function: 1) It’s incredibly slow and 2) It doesn’t exist in Theano. Both of those can be solved, even though they’re not trivial. Unfortunately einsum does not special-case the 1- and 2- argument operations like matrix multiplication, even though in principle they could. Part of the solution is to transform the format string to a canonical form (explicit output specification, no spaces, lettering ordered a-zA-Z), detect common cases like “ab,bc->ac” and use the functions that are optimized for them. Then you’d only need to think once about transpositions, when you’re writing the einsum special case.
LikeLiked by 1 person
Thanks Olexa, when I modified my MLP assignment to do support batches things started getting a bit tricky… seems like this einsum thing makes life much easier.
LikeLike
Loved this post, but frankly wept upon reading your note on performance. Hopefully just a question of time. Again, thank-you!
LikeLike
If it makes you feel slightly better, since I wrote this more than a year ago, Numpy has gone from version 1.10 to 1.13, and in the meanwhile some effort has gone into `einsum()` optimization. See here: https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.einsum.html
LikeLiked by 1 person
Great article. You summarized the use of einsum() quite understandable.
A question: I am currently implementing some part of einstein summation for sparse multidimensional arrays. Can you suggest anything to read on algorithms or optimizations?
Thanks!
LikeLike
Ow, this will be very difficult. Finding the tensor contraction order that maximizes sparsity is probably even _harder_ than finding the order that minimizes (dense) FLOPs. To give you a sense of how hard this might be, the optimal solution for the dense MCOP (Matrix Chain Ordering Problem) exists (you can find it here: http://www.cs.ust.hk/mjg_lib/bibs/DPSu/DPSu.Files/0211028.pdf) but it took years to find, relies on polygonal triangulations, and that problem is still a tiny special case of Einsum in general: `np.einsum(“ij,jk,kl,lm,mn->in”, A, B, C, D, E)` for any number of matrices multiplied side-by-side.
The general case (any tensor can interact with any other tensor, any index may be free) isn’t even close to solved for dense matrices, and so typically people just search for optimal contractions by dynamic programming if they have the time.
For sparse matrices you’d actually need to look at the matrix’s contents _on top of_ the shape, and compute in some complex manner the sequence of contractions that keeps sparsity as high as possible. I’m aware of no research on how to do that.
Of course, if you only employ (batches) of matrices, then you could write yourself a wrapper around einsum() that detects (batches of) special cases and forwards them to (batches of) sparse BLAS calls.
LikeLike
Thanks a lot for the detailed answer (and sorry for my late reply). I’ll try to write one anyways, maybe I can find a good chaning algorithm for my my special case.
Probably one can learn a lot from relational algebra research. A einstein sum is not very different from a combination of inner- and outer joins.
Processing batches of matrices with BLAS will probably perform quite bad because typically data points in my tensors are very far from each other and not clustered.
LikeLike
Reblogged this on Artificial Intelligence Research Blog.
LikeLike
I’m doing some high dimension matrix multiplication using `y = np.einsum(‘abcd,cd’, A, x)`. Do you know of any elegant method of finding A_inv such that `x = np.einsum(‘abcd,cd’, A_inv, y)`, or do I have to flatten A to find its inverse?
LikeLike
The spec you gave is equivalent to ‘abcd,cd->ab’, which doesn’t seem like a matrix multiplication… it seems more like a sort of matrix-vector product where the “matrix” has a*b “rows” and c*d “columns”, the input “column vector” has c*d “rows”, and the result column vector has a*b “rows”. I use quotes because those columns and rows are fractured into two dimensions each.
If you’re sure you’re looking for an actual matrix inverse, einsum can’t do it. You’d have to flatten the matrix to 2D and use LAPACK or some other package to invert that matrix, then reshape the output. The spec you’d need to use is actually ‘abcd,ab’, or more explicitly ‘abcd,ab->cd’.
If what you’re looking for is only A_inv times a vector, that’s called solving a system of linear equations. LAPACK, and other numerical packages as well, do offer linear equation *solvers*, which are cheaper and more numerically stable than an explicit matrix inverse followed by a matrix-vector multiply. You’d still need to flatten the matrix to 2D.
LikeLike
Thanks. Flattening, inverting, and reshaping did what I need.
The application here was in the digital imaging domain. I thought I was being clever by using einsum to process images in their 2D form instead of vectorizing, multiplying, and reshaping.
Looking back, I think I made it harder on myself translating the source material (which is flattened vectors and regular matrix multiplication) to these tensor forms. The expressions are definitely harder to write down.
LikeLike
Thank-you so much for writing this. The numpy documentation is indeed very opaque for a beginner. I found this article much clearer.
LikeLike
Pingback: MemoryError on row-wise outer products in Numpy – PythonCharm
Thanks for posting this! I
I always suspected there had to be a better way to manage the plethora of products high rank arrays impose. There’s a fine line between generality and utility. Both you and einsum have hit the sweet spot.
LikeLike
Reblogged this on My Blog.
LikeLike
Pingback: Phil 1.20.19 | viztales
Pingback: New top story on Hacker News: Einstein Summation in Numpy – Golden News
Pingback: New top story on Hacker News: Einstein Summation in Numpy – Hckr News
Pingback: New top story on Hacker News: Einstein Summation in Numpy – World Best News
Pingback: New top story on Hacker News: Einstein Summation in Numpy – Outside The Know
Pingback: New top story on Hacker News: Einstein Summation in Numpy – Latest news
Pingback: New top story on Hacker News: Einstein Summation in Numpy – News about world
Pingback: Einsum Is All You Need – Einstein Summation in Deep Learning – gutuka
Pingback: Einsum Is All You Need – Einstein Summation in Deep Learning - Entertaining WE
Pingback: How Einstein Summation Works and Its Applications in Deep Learning - AI+ NEWS
This is a very very helpful post. Thanks for taking the time to write it.
LikeLike
This article was really explaining! I have easily understood einsum notation from what you wrote. Thank you for your effort to create this!
LikeLike
Pingback: 用 Python 計算內積的幾種做法 – 樹洞 Tree Hole 2.0
This post helped me coding my first einstein summation. I calculated the errors of a fit by propagating the covariance of the parameter estimators. After spending too much time with numpy matrix multiplication, I manage to solve my problem with einsum straightforwardly! Thank you for writing down this, I found the numpy documentation rather obscure. Cheers
LikeLike
Errata:
Matrix inner product “ab,ab->” (If you pass twice the same argument, it becomes a matrix L2 norm)
Should be the square of the L_2 Norm (as you would get the sum of squares, and still need to take the sqrt)
LikeLiked by 1 person