I’ve just created a new SqueezeNet-based model with Keras, which reuses some of my ideas from CUBAN, my IFT6390 project. In that project I had been using:
- “Fine” filters, run on the input, the original image (192,192).
- “Medium” filters, run on a half-sampled image (96,96). As a hack I did it with (2,2)-average pooling of the original image.
- “Coarse” filters, run on a quarter-sampled image (48,48). Again, I did it with (2,2)-average pooling of the medium image.
In CUBAN, I had been using "valid" convolutions, strides of (4,4), (2,2) and (1,1) and precisely-computed slices and offsets to get the output feature maps to be of identical size. I’d then concatenate them and let the further layers of the network choose what to do with them. I did that in the hopes of allowing the network to learn multiscale representations, increasing its robustness to scaling effects, and to let it exploit super-fine texture as well as global “look”.
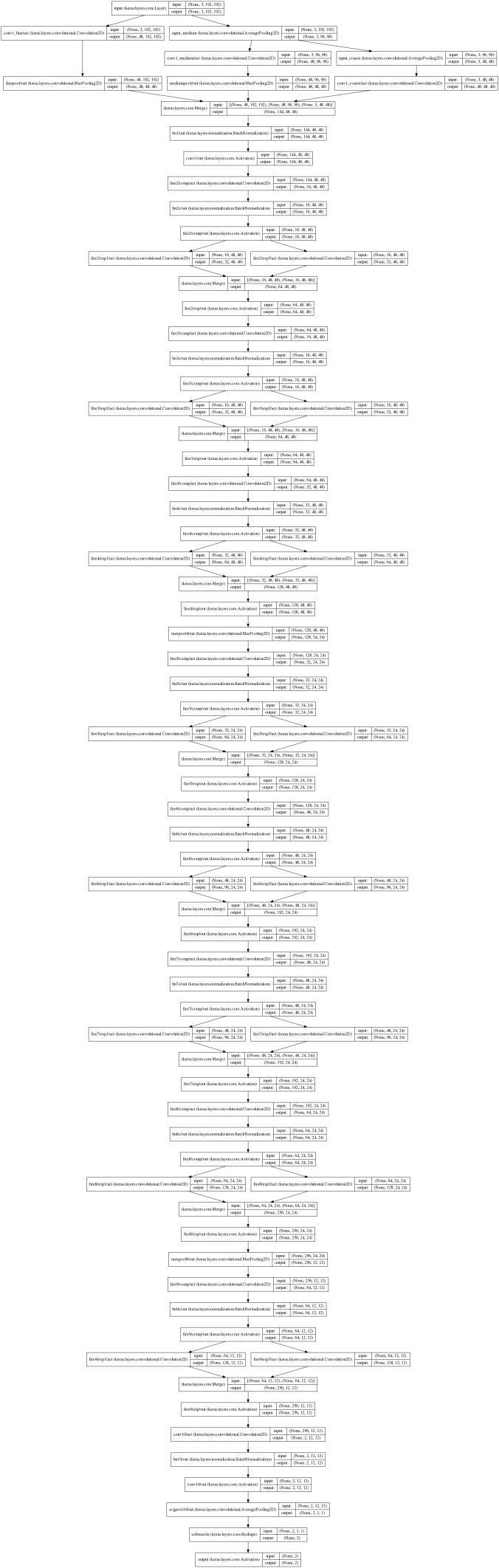
In this variant of SqueezeNet, I delete the first (7,7) convolutional layer and max-pooling, and replace it with the above series of fine/medium/coarse (7,7) filters. However, I run the convolutions in "same" mode and with (1,1) strides (no subsampling) on all three image sizes. This is indeed much more expensive, but so far has been worth the price. To make the feature maps of identical size prior to stacking, I max-pool (4,4) the fine feature map and max-pool (2,2) the medium feature map to bring them down to the coarse feature map’s size of (48,48).
In addition I’ve tacked back on Batch Normalization layers after every compression convolution, since they are extremely helpful at speeding up training.
This model, including the tangle at the input layers, is drawn here, courtesy of Keras’ visualization submodule.
As of the end of Epoch 8, about 1.5 hours into training, I have now exceeded the performance of my previous personal best, with a validation error rate of 11.160%.
As a fun distraction while my latest model trains itself, I wrote some code to visualize the first-stage features, the (7,7,3) filters for the fine/medium/coarse images. Here they are; The first 48 filters (3 rows) are fine, the next 48 are medium, and the last 48 are coarse.

Interestingly, the network seems to duplicate the same features across all three scales, instead of using texture at fine scales and general look at coarser scales. Moreover, there are several filters with no obvious use, especially the flat blue ones. But this does provide insight into how the neural network exploits its capacity.

Pingback: CUBAN-Style Input Layers: 5.76% Validation Error | Olexa Bilaniuk's IFT6266H16 Course Blog
Pingback: Trying to Scale Up to Full-Size SqueezeNet | Olexa Bilaniuk's IFT6266H16 Course Blog
Pingback: Dogs vs Cats – Parametric ReLU – 2.1% error rate | IFT6266-Deep Learning
Pingback: Final Summary | Olexa Bilaniuk's IFT6266H16 Course Blog